Loading... ## 前言 最近有个需求涉及的验证码登录,尝试过许多 OCR API 都没有什么好的效果,准确率可以说约等于 0 . 当然也可能是我没找到。 不过通过搜索还是让我发现了 [captcha_trainer](https://github.com/kerlomz/captcha_trainer) 这个项目。 项目的 About : > [验证码识别-训练] This project is based on CNN/ResNet/DenseNet+GRU/LSTM+CTC/CrossEntropy to realize verification code identification. This project is only for training the model. 项目介绍 : > 基于深度学习的图片验证码的解决方案 - 该项目能够秒杀字符粘连重叠/透视变形/模糊/噪声等各种干扰情况,足以解决市面上绝大多数复杂的[验证码场景](https://github.com/kerlomz/captcha_trainer#jump),目前也被用于其他OCR场景。 看起来不错,而且项目还提供了编译版,像我这种无基础的人也能轻松跑起来。 当然光有这个项目是完全不行的,还需要大量的训练集,才能训练出识别验证码的模型。下面我就简单的讲述下我的解决办法及思路。 ## 正文 ### 准备工作 首先是要下载好需要的一切东西。 1. [captcha_trainer 编译版](https://github.com/kerlomz/captcha_trainer/releases/tag/v1.0) 2. [部署程序](https://github.com/kerlomz/captcha_platform) 这个是用来部署训练出来的模型的 其次是准备相关环境 1. Python 3.8+ 2. Windows 10 ### 准备训练集 每个网站的验证码复杂度都是不一样的,有的很复杂有的很简单。复杂就意味着需要更多的样本才能训练出准确率高的模型。但这少说几万的训练集从何而来呢? 下面我说说我的思路: 1. 首先分析网站是如何生成验证码的,比如用了什么开源的验证码生成方案,或者是自己写的验证码生成方案。 2. 找到该网站验证码的生成方法后就好办了,比如使用了 Kaptcha 这个项目,这个时候就只需要去实际模拟一下生成过程,就可以获得不少的样本。但是通过这样生成的训练集去训练出来的模型,在实际使用中会发现准确率很低!这是因为,体同样的项目,你设置的参数和网站的参数是很难保证一致的,只能做到相似。 但不用怕,你可以用这个成功率低的模型,写个爬虫去验证实际的网站来重新采集训练集。即使只有30%的准确率,也是足够的,验证 1000 次便能收集到300个样本,这样多运行几次便能获得足够的样本再训练一次了。 因为这次是使用的是网站生成的验证码来训练的模型,在实际使用中准确率就会十分高了。 3. 如果网站是使用的自己写的方案来生成验证码的话,就只能选择自己写脚本来收集验证码了,可以先自己标注 1000 个样本,拿这 1000 去训练一个模型,不需要多高的准确率,10% 都足够。再和上面说到的一样,用这个模型去网站实际验证然后收集样本重新训练。 如果觉得自己标注麻烦,也可以选择一些平台来做,只是需要付出相应的金钱。 ### 开始训练 训练集准备完毕,现在就开始训练了。这里我准备了我自己使用过的训练集给大家实际体验一下。 点击 [Python简单解决验证码问题](http://ad.myelf.club/?file=zb37ue47 "Python简单解决验证码问题") 即可下载 **注:`_test`结尾的是验证集,其他的是训练集** 解压之前下载的编译版,运行 app.exe 运行之后会弹出两个框框,一个黑一个白。黑色可以查看训练的实时进度,白色是用来配置的。 对于一般的来说,默认配置便可。需要修改的只有训练集路径和验证集路径,已经标签数。标签数是指验证码个数,比如四位验证码就设置为4. 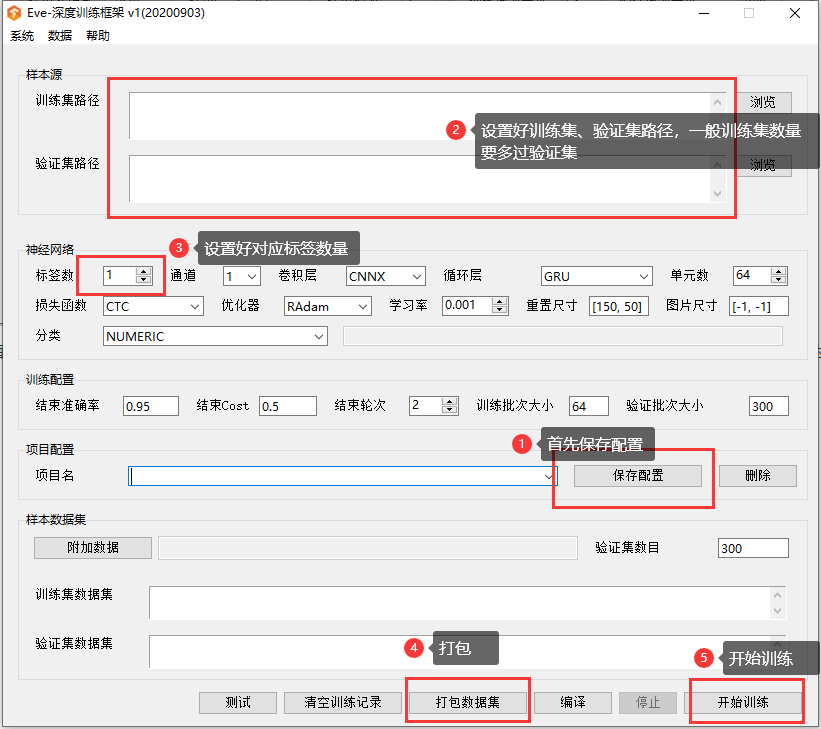 其他如何配置就不展开说了。自己稍加研究即可。 ### 部署 训练完成之后便是部署了,首先去 app.exe 这个文件所在目录下找到 projects 文件夹,这个文件夹下保存了你刚刚训练的模型。 进入对应项目名,将 out 目录下的两个文件夹复制,然后到之前下载的部署程序编译版目录下,运行 captcha_platform_tornado.exe 程序即可。 接下来就可以调用对应接口测试了。具体使用请结合 [史上最强Python验证码识别|开源+通用识别模型](https://segmentfault.com/a/1190000022812969) 文章查看。 这里说一下 SDK 的调用方式,即集成到你的 Python 项目中: 首先安装 muggle_ocr 模块(Python最好是3.8+ 64位) 示例代码: ``` import time # 1. 导入包 import muggle_ocr """ 使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种 其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码 """ # 打开印刷文本图片 with open(r"test1.png", "rb") as f: ocr_bytes = f.read() # 打开验证码图片 with open(r"test2.jpg", "rb") as f: captcha_bytes = f.read() # 2. 初始化;model_type 可选: [ModelType.OCR, ModelType.Captcha] sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR) # ModelType.Captcha 可识别光学印刷文本 for i in range(5): st = time.time() # 3. 调用预测函数 text = sdk.predict(image_bytes=ocr_bytes) print(text, time.time() - st) # ModelType.Captcha 可识别4-6位验证码 sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha) for i in range(5): st = time.time() # 3. 调用预测函数 text = sdk.predict(image_bytes=captcha_bytes) print(text, time.time() - st) """ 使用自定义模型 支持基于 https://github.com/kerlomz/captcha_trainer 框架训练的模型 训练完成后,进入导出编译模型的[out]路径下, 把[graph]路径下的pb模型和[model]下的yaml配置文件放到同一路径下。 将 conf_path 参数指定为 yaml配置文件 的绝对或项目相对路径即可,其他步骤一致,如下示例: """ with open(r"test3.jpg", "rb") as f: b = f.read() sdk = muggle_ocr.SDK(conf_path="./ocr.yaml") text = sdk.predict(image_bytes=b) ``` ### 结语 这绝对是一个很方便的项目,即使我这样的小白也能快速上手。 ### 相关 [史上最强Python验证码识别|开源+通用识别模型](https://segmentfault.com/a/1190000022812969) https://www.jianshu.com/p/1f2f7c47e812 https://gitee.com/rwxing/springbootKaptcha https://www.freebuf.com/articles/web/238701.html Last modification:October 20th, 2020 at 12:56 pm © 允许规范转载 Support If you think my article is useful to you, please feel free to appreciate ×Close Appreciate the author Sweeping payments
学到了,太难了
又发现一个好站,收藏了~以后会经常光顾的Σ(っ °Д °;)っ
博客真好看,来混个脸熟ヾ(≧∇≦*)ゝ